A stochastic process, or sometimes random process, is the counterpart of a deterministic process (or deterministic system) considered in probability theory. Instead of dealing only with one possible 'reality' of how the process might evolve under time (as it is the case, for example, for solutions of an ordinary differential equation), in a random process there is some indeterminacy in its future evolution described by probability distributions. This means that even if the initial condition (or starting point) is known, there are more possibilities the process might go to, but some paths are more probable and others less.
In the simplest possible case ('discrete time'), a stochastic process amounts to a sequence of random variables known as a time series (for example, see Markov chain). Another basic type of a stochastic process is a random field, whose domain is a region of space, in other words, a random function whose arguments are drawn from a range of continuously changing values. One approach to stochastic processes treats them as functions of one or several deterministic arguments ('inputs', in most cases regarded as 'time') whose values ('outputs') are random variables: non-deterministic (single) quantities which have certain probability distributions. Random variables corresponding to various times (or points, in the case of random fields) may be completely different. The main requirement is that these different random quantities all have the same 'type'. Although the random values of a stochastic process at different times may be independent random variables, in most commonly considered situations they exhibit complicated statistical correlations.
Familiar examples of processes modeled as stochastic time series include stock market and exchange rate fluctuations, signals such as speech, audio and video, medical data such as a patient's EKG, EEG, blood pressure or temperature, and random movement such as Brownian motion or random walks. Examples of random fields include static images, random terrain (landscapes), or composition variations of an inhomogeneous material.
Formal definition and basic properties
Given a probability space
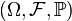 , a stochastic process (or random process) with state space X is a collection of X-valued random variables indexed by a set T ("time"). That is, a stochastic process F is a collection
, a stochastic process (or random process) with state space X is a collection of X-valued random variables indexed by a set T ("time"). That is, a stochastic process F is a collection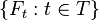
where each Ft is an X-valued random variable.
A modification G of the process F is a stochastic process on the same state space, with the same parameter set T such that
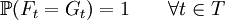 .
.Definition
Let F be an X-valued stochastic process. For every finite subset
 , we may write
, we may write  , where
, where 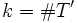 and the restriction
and the restriction 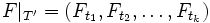 is a random variable taking values in
is a random variable taking values in 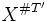 . The distribution
. The distribution 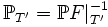 of this random variable is a probability measure on
of this random variable is a probability measure on 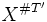 . Such random variables are called the finite-dimensional distributions of F.
. Such random variables are called the finite-dimensional distributions of F.Under suitable topological restrictions, a suitably "consistent" collection of finite-dimensional distributions can be used to define a stochastic process (see Kolmogorov extension in the next section).
Finite-dimensional distributions
In the ordinary axiomatization of probability theory by means of measure theory, the problem is to construct a sigma-algebra of measurable subsets of the space of all functions, and then put a finite measure on it. For this purpose one traditionally uses a method called Kolmogorov extension.
There is at least one alternative axiomatization of probability theory by means of expectations on C-star algebras of random variables. In this case the method goes by the name of Gelfand-Naimark-Segal construction.
This is analogous to the two approaches to measure and integration, where one has the choice to construct measures of sets first and define integrals later, or construct integrals first and define set measures as integrals of characteristic functions.
Constructing stochastic processes
The Kolmogorov extension proceeds along the following lines: assuming that a probability measure on the space of all functions
 exists, then it can be used to specify the probability distribution of finite-dimensional random variables
exists, then it can be used to specify the probability distribution of finite-dimensional random variables 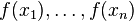 . Now, from this n-dimensional probability distribution we can deduce an (n − 1)-dimensional marginal probability distribution for
. Now, from this n-dimensional probability distribution we can deduce an (n − 1)-dimensional marginal probability distribution for 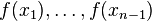 . There is an obvious compatibility condition, namely, that this marginal probability distribution be the same as the one derived from the full-blown stochastic process. When this condition is expressed in terms of probability densities, the result is called the Chapman-Kolmogorov equation.
. There is an obvious compatibility condition, namely, that this marginal probability distribution be the same as the one derived from the full-blown stochastic process. When this condition is expressed in terms of probability densities, the result is called the Chapman-Kolmogorov equation.The Kolmogorov extension theorem guarantees the existence of a stochastic process with a given family of finite-dimensional probability distributions satisfying the Chapman-Kolmogorov compatibility condition.
The Kolmogorov extension
Recall that, in the Kolmogorov axiomatization, measurable sets are the sets which have a probability or, in other words, the sets corresponding to yes/no questions that have a probabilistic answer.
The Kolmogorov extension starts by declaring to be measurable all sets of functions where finitely many coordinates
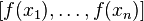 Yn. In other words, if a yes/no question about f can be answered by looking at the values of at most finitely many coordinates, then it has a probabilistic answer.
Yn. In other words, if a yes/no question about f can be answered by looking at the values of at most finitely many coordinates, then it has a probabilistic answer.In measure theory, if we have a countably infinite collection of measurable sets, then the union and intersection of all of them is a measurable set. For our purposes, this means that yes/no questions that depend on countably many coordinates have a probabilistic answer.
The good news is that the Kolmogorov extension makes it possible to construct stochastic processes with fairly arbitrary finite-dimensional distributions. Also, every question that one could ask about a sequence has a probabilistic answer when asked of a random sequence. The bad news is that certain questions about functions on a continuous domain don't have a probabilistic answer. One might hope that the questions that depend on uncountably many values of a function be of little interest, but the really bad news is that virtually all concepts of calculus are of this sort. For example:
all require knowledge of uncountably many values of the function.
One solution to this problem is to require that the stochastic process be separable. In other words, that there be some countable set of coordinates {f(xi)} whose values determine the whole random function f.
The Kolmogorov continuity theorem guarantees that processes that satisfy certain constraints on the moments of their increments are continuous.
boundedness
continuity
differentiability Examples and special cases
A notable special case is where the time is a discrete set, for example the nonnegative integers {0, 1, 2, 3, ...}. Another important special case is
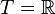 .
.Stochastic processes may be defined in higher dimensions by attaching a multivariate random variable to each point in the index set, which is equivalent to using a multidimensional index set. Indeed a multivariate random variable can itself be viewed as a stochastic process with index set T = {1, ..., n}.
The time
The paradigm continuous stochastic process is that of the Wiener process. In its original form the problem was concerned with a particle floating on a liquid surface, receiving "kicks" from the molecules of the liquid. The particle is then viewed as being subject to a random force which, since the molecules are very small and very close together, is treated as being continuous and, since the particle is constrained to the surface of the liquid by surface tension, is at each point in time a vector parallel to the surface. Thus the random force is described by a two component stochastic process; two real-valued random variables are associated to each point in the index set, time, (note that since the liquid is viewed as being homogeneous the force is independent of the spatial coordinates) with the domain of the two random variables being R, giving the x and y components of the force. A treatment of Brownian motion generally also includes the effect of viscosity, resulting in an equation of motion known as the Langevin equation.
If the index set of the process is N (the natural numbers), and the range is R (the real numbers), there are some natural questions to ask about the sample sequences of a process {Xi}i ∈ N, where a sample sequence is {X(ω)i}i ∈ N.
Similarly, if the index space I is a finite or infinite interval, we can ask about the sample paths {X(ω)t}t ∈ I
What is the probability that each sample sequence is bounded?
What is the probability that each sample sequence is monotonic?
What is the probability that each sample sequence has a limit as the index approaches ∞?
What is the probability that the series obtained from a sample sequence from f(i) converges?
What is the probability distribution of the sum?
What is the probability that it is bounded/integrable/continuous/differentiable...?
What is the probability that it has a limit at ∞
What is the probability distribution of the integral?
 See also
See also
No comments:
Post a Comment